
算法基础(一)基本的数据结构(数组、集合、字典、字符串)
数组
NSArray与NSMutableArray
在Objective-C中,数组被分成NSArray(不可变数组)与NSMutableArray(可变数组)
- 数组是一个对象,是任意类型对象地址的集合,OC的数组可以存储不同类型的对象。
- OC的数组只能存储对象,不能存放 简单的数据类型(int, float, NSInteger…)除非通过一些手段把简单数据类型变成对象。在C语言中的数组可以保存任意类型的数据。
如果想要直接使用数据类型可以在基本类型前加@,将c的字符串或者基本类型(int、double)转化为oc的对象。如果基本类型变量作为元素并添加@则是不正确的。 - 存储的内存是连续的(这取决于你的元素是在数组创建时才初始化元素,如果
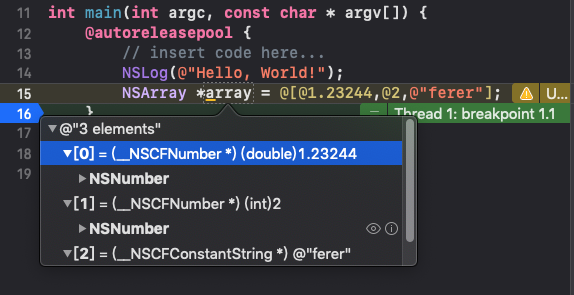
元素变量事先初始化过或者你的初始化的方式不一致,则可能不会是连续,如果元素的类型不同,他的内存地址在数组遍历上也会不一定是连续的,但是相同的类型内存地址上会体现连续)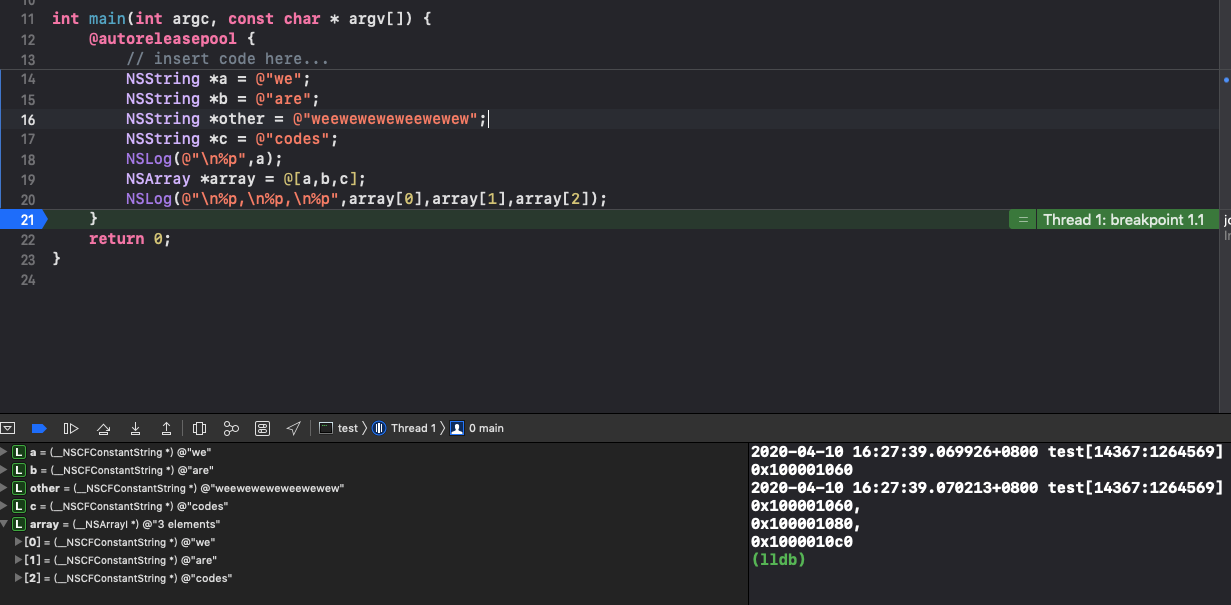
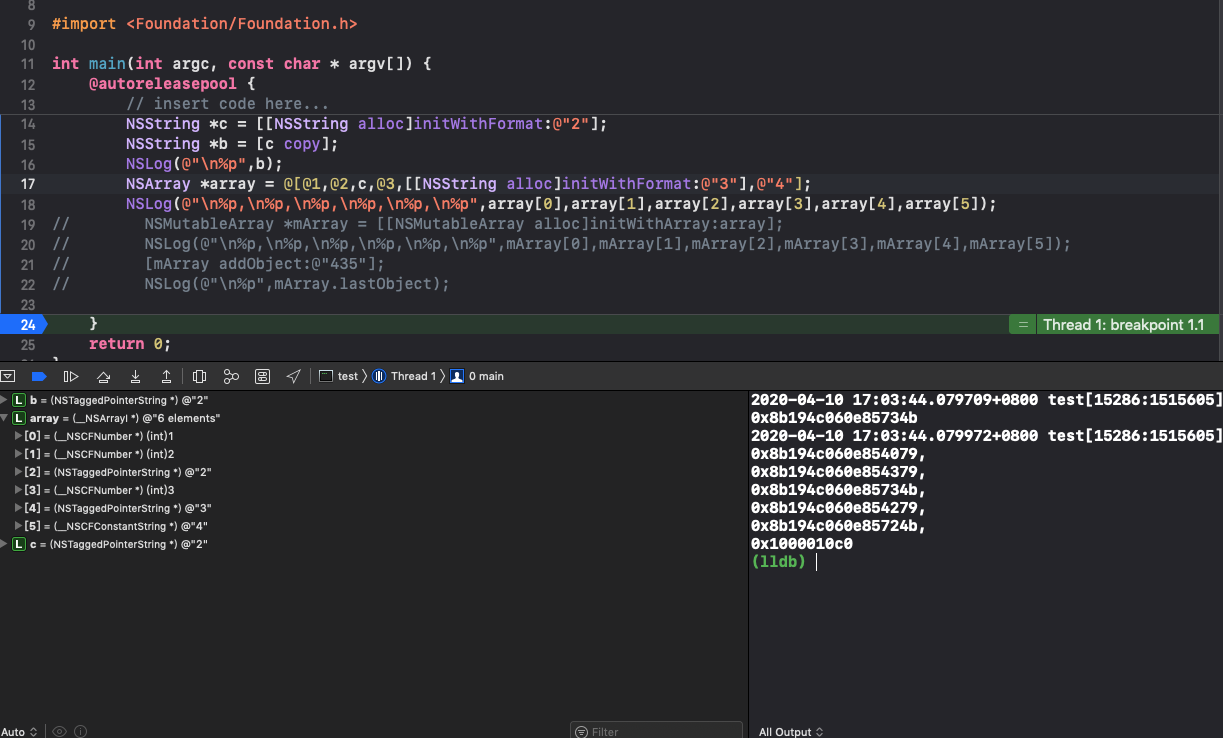
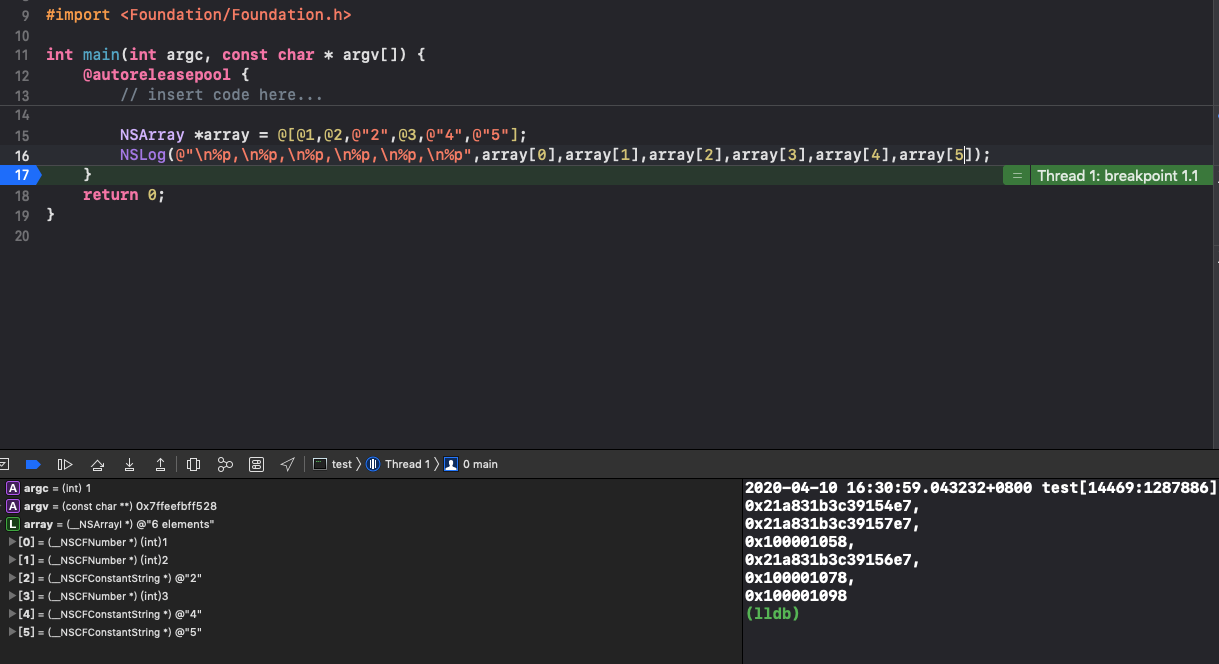
可变数组在内存上的体现也是如此,只不过NSMutableArray可以支持不确定的数量以及动态的变化(增删改)。变化形式上比NSArray要好。
内存管理ARC会管理对象的释放以及循环利用(),如果想要对象变量开辟两个内存地址,需要理解copy与mutableCopy。
这里的内存地址的样式不同,也体现了栈区和堆区的概念。拖站阅读:
ios - 大家中午好,xcode 中如何查看一个对象是在堆区还是在栈区? - SegmentFault 思否
OC中栈区与堆区的内存概念解析 - 航大大 - 博客园
这里对于数组的用法不做过多的介绍,后期补充。
Swift的Array
在Swift中,Array整合了OC的可变数组与不可变数组,但是他的实现方式有三种:
ContiguousArray
The ContiguousArray type is a specialized array that always stores its elements in a contiguous region of memory. This contrasts with Array, which can store its elements in either a contiguous region of memory or an NSArray instance if its Element type is a class or @objc protocol.
If your array’s Element type is a class or @objc protocol and you do not need to bridge the array to NSArray or pass the array to Objective-C APIs, using ContiguousArray may be more efficient and have more predictable performance than Array. If the array’s Element type is a struct or enumeration, Array and ContiguousArray should have similar efficiency.
For more information about using arrays, see Array and ArraySlice, with which ContiguousArray shares most properties and methods.
——来自Apple官方文档。
翻译
“邻接数组”类型是一个 总将元素存储在一个相邻的内存区域 的专用的数组。这与“Array”有所不同,如果“Array”的数组元素类型是类类型(class)或者声明@objc的协议(@objc protocol)的话,可以将其元素存储在一个相邻的内存区域或“NSArray”实例中。
如果数组的“元素”类型是一个类或声明@objc的协议,并且不需要将数组桥接为“NSArray”或将数组传递给Objto-C API,则使用“ContiguousArray”可能比“Array”更有效且具有更好的性能。如果数组的“元素”类型是结构或枚举,则“Array”和“ContiguousArray”应该具有类似的效率。
总结上面的有以下用法:
1. 数组存储 基本类型、结构体、枚举 时,Array和ContiguousArray是差不多的;
2. 当存储 class、@objc protocol 时,需要考虑两种情况,如果不用桥接不用传到OC-API上的时候,那么用ContiguousArray更快点。
3. 如果用到了桥接或者声明@objc 传递到OC-API,那么使用Array更快点。
Array
数组(Array)是一串有序的由相同类型元素构成的集合,数组中的集合元素是有序的,可以重复出现。在Swift中数组类型是Array,是一个泛型集合。数组分成:可变数组和不可变数组,分别使用let修饰的数组是不可变数组,使用var修饰的数组是可变数组。
注意,swift的严格类型检查使得Array需要确定元素类型,即便你使用Any和AnyObject来使得支持不同的类型,但是出现复杂的类强制解析类型会导致crash,甚至你格式化字符串输出时产生编译报错因为Any和AnyObject不支持CVararg。
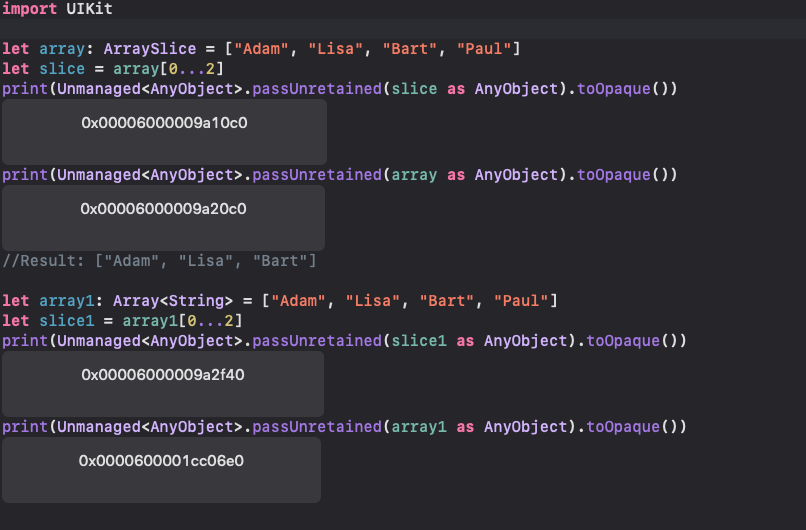
ArraySlice
ArraySlice 既是Array的一部分又是独立的一个对象,主要用于把一个数组中间的几个数据切片到一个新的数组中。
1 | let array: ArraySlice = ["Adam", "Lisa", "Bart", "Paul"] |
用数组实现栈
在Swift上用数组拓展程更多的数据结构是合适并且拥有方便的操作方法。
1 | class Stack { |
Swift中Array冷门方法
reserveCapacity
如果明确的知道一个数组的容量大小,可以调用这个方法告诉系统这个数组至少需要的容量,避免在数组添加元素过程中重复的申请内存。
1 | var alphabet = [String]() |
但是,通常情况下我们并不能确定这个数组最后要存储多少元素。如果你创建一个包含四个元素的数组,Swift 将会分配足够的内存去存储这仅有的4个元素。所以,数组的 count 和 capacity 都是4。
现在,你想去添加第五个元素。但数组并没有足够的长度去添加它,所以数组需要寻找一块足够存放五个元素的内存,然后将数组的4个元素拷贝过去,最后再拼接第五个元素。它的时间复杂度是O(n)。
为了避免不断重新分配内存, Swift 对数组的容量采用了一种几何增加模式(a geometric allocation pattern) 。这是一种非常好的方式,它成倍的增加数组的容量避免多次重新分配内存的问题。当你在容量为4的数组中添加第五个元素的时候,Swift 将会将数组的长度增加为 8 。每当你超出数组的长度范围,它将会以32、64等成倍的依次增加。
如果你知道你将要存储512个元素,你可以使用 reserveCapacity() 函数来通知 Swift。然后 Swift 会立刻分配一块可以存储512个元素的内存给数组,而不是创建一个小数组,再多次重新分配内存。
拓展阅读:Swift 中的 Array 性能比较: append vs reserveCapacity(译) | 码农网
lexicographicallyPrecedes
Lexicographic 是词典的意思。这个方法声明在 AnyCollection 里。会按照顺序比较两个集合元素的大小(它只按照两个集合对应的元素进行,元素多的集合后面没有对应的元素这不算比较)。
1 | let array1 = [1,2,1,455454] |
partition
partition 会根据条件把集合里的元素重新排序,符合条件的元素移动到最后,返回一个两个部分分界元素的索引。
1 | var numbers = [30, 40, 20, 30, 30, 60, 10] |
sequence(first: next: )
根据next里的闭包来生成下一个元素,和reduce完全相反。特别的是这个函数返回的是一个 UnfoldSequence ,即里面的值是lazy的,只要在访问时才生成,这也可能是一个无限的队列。
1 | for x in sequence(first: 0.1, next: { $0 * 2 }).prefix(while: { $0 < 4 }) { |
似乎特别适合用来寻祖,当next闭包返回的是nil时队列就终止了:
1 | for view in sequence(first: someView, next: { $0.superview }) { |
elementsEqual
用来判断两个队列的是否拥有相同的元素,并且顺序是一致的
1 | let a = 1...3 |
集合(Set)
集合(Sets)是无序无重复数据的集。
集合的创建元素也需要类型统一,你定义了元素中如有重复,会把重复的后者排除。
由集合的特性便有一些方法可以对集合进行操作。
* **intersection(_:)**:根据两个集合中都包含的值创建的一个新的集合。
* **symmetricDifference(_:)**:根据在一个集合中但不在两个集合中的值创建一个新的集合。
* **union(_:)**:根据两个集合的值创建一个新的集合。
* **subtracting(_:)**:根据不在该集合中的值创建一个新的集合。
* **==**:判断两个集合是否包含全部相同的值。
* **isSubset(of:)**:判断一个集合中的值是否也被包含在另外一个集合中。
* **isSuperset(of:)**:判断一个集合中包含另一个集合中所有的值。
* **isStrictSubset(of:)**:判断一个集合是否是另外一个集合的子集合,并且两个集合并不相等。
* **isStrictSuperset(of:)**:判断一个集合是否是另外一个集合的父集合,并且两个集合并不相等。
* **isDisjoint(with:)**:判断两个集合是否不含有相同的值(是否没有交集)。
1 | let oddDigits: Set = [1, 3, 5, 7, 9] |
可哈希化
- 一个类型如果想要存储在集合中,那么该类型必须是可哈希化的。也就是说,该类型必须提供一个方法来计算它的哈希值。
- 哈希值是 Int类型,相等对象的哈希值必须相同。比如:a==b,那么必定有 a.hashValue == b.hashValue。
- Swift的所有基本类型(如 String,Int,Double,Bool)默认都是可哈希化的,可以作为集合的值的类型或者字典的键的类型。没有关联值的枚举成员值默认也是可哈希化的。
哈希化可以使得一个对象他的唯一性以及完整性。散列函数能帮助你了解哈希值的由来。那么我们自定义类型如何进行哈希化:- 如果想要自定义的类型作为集合的值类型或者是字典的键类型,那么这个自定义类型必需符合 Swift标准库中的 Hashable协议。符合 Hashable协议的类型需要提供一个类型为 Int的可读属性 hashValue。
- 因为 Hashable协议符合 Equatable协议,所以遵循该协议的类型也必须提供一个”是否相等”运算符(**==)的实现。这个 Equatable协议要求任何符合 == 实现的实例间都是一种相等的关系。也就是说,对于a、b、c** 三个值来说,**==**的实现必须满足下面三种情况:
- 自反性:a == a
- 对称性:a == b 意味着 b == a
- 传递性:a == b && b == c意味着 a == c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//自定义对象
struct User {
let name: String
let age: Int
}
//自定义对象需要符合Hashable协议
extension User: Hashable {
var hashValue: Int { return name.hashValue ^ age.hashValue }
}
//由于Hashable协议又符合Equatable协议,所以还要提供一个"是否相等"运算符(==)的实现
func ==(lhs: User, rhs: User) -> Bool {
return lhs.name == rhs.name && lhs.age == rhs.age
}
let a = User(name: "牛大哥", age: 55)
let b = User(name: "马小弟", age: 20)
let c = User(name: "牛大哥", age: 55)
let arr = [ a, b, c ]
let set = Set(arr)
print("arr里元素个数:\(arr.count)")
print("set里元素个数:\(set.count)")
//arr里元素个数:3
//set里元素个数:2
例题分析
给出一个整型数组和一个目标值,判断数组中是否有两个数之和等于目标值。
暴力的方式数组中的两个值遍历然后匹配,而且还要存储匹配结果再跟之前的进行比较。这种方法的时间复杂度为O(n2)
我们可以采用集合来优化时间复杂度。在遍历数组的过程中,用集合每次保存当前值。假如集合中有一个数等于目标值减去当前值,则证明在之前的遍历中一定有一个数与当前值之和等于目标值,这种方法的时间复杂度为O(n)
1 | func twoSum(nums: [Int],_ target: Int) -> Bool { |
字典
字典(Dictionaries)是无序的键值对的集。
使用字典,应该注意一个数据的key-value怎么样存储是有它的实际意义,以及他是否可以使用字典。如果key的value他需要存储多个值或者通过值来确定值的方式,需要考虑其他的实现方式或者优化代码。
1 | var dictionary: [String:Int] = [:] |
上个例题升级
给定一个整型数组中有且仅有两个数之和等于目标值,求这两个数在数组中的序号。
这里的解决方法和上面相似,为了记录序列号,我们可以使用字典,使得时间复杂度仍然保持不变。
1 | func twoSum(nums: [Int],_ target: Int) -> [Int] { |
字符串
Swift中,字符串已String对象表现出来。 这里对于String的一些用法进行收集,能在字符串的处理中帮助你快速做出结果。
1 |
|
例题分析
将字符串“the sky is blue”转变为“blue is sky the”。
- 思路:这里有两种想法,一种全部倒过来,然后对单词再颠倒过去
另一个是先分词(一段话中的单词存成数组),然后倒序输出。 - 我们选择第一个方法,使得时间复杂度为O(n)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18func reverseWords(str: String?) -> String? {
guard let str = str else {
return nil
}
let reversedStr = str.reversed()
var result = ""
var temp = ""
for cha in reversedStr {
temp.append(cha)
if cha == " " {
result.append(String(temp.reversed()))
temp = ""
}
}
return result
}